By Greg Eves
Introduction
In my previous article I highlighted a number of common issues with OpenLink based logging and demonstrated the potential impact they might have on a typical instance. In this article I’m going to describe a strategy for keeping on top of unwieldy core OpenLink logs. If your instance of Endur or Findur has an error logs directory that looks like the screen-shot below, then this article is for you.

Let’s first consider why we might want to reduce the amount of logs being generated by our OpenLink application. In my last article I talked through a scenario where a user was experiencing an issue with a report. The excessive size of the core log made it difficult to open and find the pertinent error. I also crudely calculated the cost of logging to be around 1hour per gigabyte where logs are output to a remote location. Most of this cost can be attributed to the speed of the network. So if we reduce the quantity of logging output we should improve the speed of our application by around 1 hour per gigabyte saved. We’ll make it easier for those supporting the application to open and find the log information they need and make it faster to import our now reduced output into any analytics tools we might want to use. We’ll also save a bit of disk space and cut down our network traffic.
Retrospective Analysis
Now that the benefits are clear, how might we tackle the situation like the above? We can see that the server users in the screen shot are generating around 200mb of data on a daily basis, but the screen-shot does not tell the whole story, the folder also contains the log files for every other user and whilst not as large as the server users the still contain a significant amount of logging data.
We could start manually trawling the files targeting what we perceive to be the most often repeated errors. Not only is this approach extremely tedious, it is also inefficient. With such high volumes of data it is extremely difficult to determine which errors are most prevalent. Instead of guessing, we can use Elastic Search and more specifically the ELK stack to do the hard work for us to find the most prevalent log messages extremely quickly and accurately.
Elastic Search is a distributable, scalable server based analytics engine with a Lucene back-end. It is able to process and store unstructured data that can then be analysed extremely quickly. Combined with LogStash – used for parsing log files, and Kibana – the presentation layer, it makes for an accurate and efficient framework for making sense of log files, even those generated by OpenLink.
The ELK stack is available under an open source licence and can be downloaded from here, it is also recommended that you have the latest version of Java installed. In a proof of concept/experimental type context, both Elastic Search and Kibana can be started with their default configuration to run on a single node. In order to get LogStash running and posting logs to Elastic Search you will need a config file to tell it where to look for the logs and how they should be parsed. Whilst the OpenLink core logs are not perfect in terms of their machine readability it is possible to construct a series of regular expressions that will split each message into its component parts, enabling LogStash to turn a message like this:
31 Jan 2016 17:29:59:Script Engine 2: ERROR – >: OL:0-0020 Error encountered, rolling back Transaction |
Into a JSON format that is consumable by Elastic Search that looks something like this:
“_index”: “logstash-2016.01.31”,
“_score”: null,
“level”: “ERROR”, “code”: “OL:0-0020”, “msg”: “Error encountered, rolling back Transaction\r”, “unified_msg”: “Error encountered, rolling back Transaction\r”, “type”: “OpenLink Core” |
At this point it is worth noting that the core OpenLink core logs have a fundamental flaw in their design. Unfortunately the timestamp is output in the format HH:mi:ss and does not include milliseconds.
Obviously a lot can happen in a second, in my last article I showed that when writing to disk we could hit a rate of 20,000 messages per second, which means we could have up to 20,000 messages per user in Elastic Search all with the same timestamp. For the purpose of this article, this does not pose a significant issue. However, this is something that should be kept in mind when using Elastic Search to perform granular order of execution analysis – Without further work, the messages in Elastic Search may appear in the wrong order.
OpenLink has introduced (V10.0r2) an environment variable that, when you read the description suggests it might solve this problem. However, instead of simply adding milliseconds to the existing timestamp, it adds three new columns. The first shows the time in seconds.milliseconds since the process started. The second shows the time in seconds.milliseconds since the last message for the same process and the third shows what is described as a cumulative delta figure in seconds.milliseconds. When testing this variable I found it of little use, the millisecond output in all three columns is not aligned to the base timestamp so could not be reliably appended to or combined with the existing timestamp. In my view OpenLink should enhance or provide an environment variable that enables milliseconds to be appended to the timestamp in core log messages to make the integration of analysis tools much easier. As it stands the alternative method I would use to overcome this issue when processing logs in real time would be to let LogStash generate the timestamp based on the server time where LogStash is running, the timestamps would not precisely line up with those in the logs, but at least they would be in the correct order for the same user. If order of execution analysis were being performed across several users (i.e. from multiple log files) the issue of building a true order of execution will remain as it would if you were trying to build an order of execution across multiple core log files manually.
For administration tasks it is a good idea to use a browser based GUI such as Elastic HQ, this makes tasks such as deleting indices and monitoring performance and size a lot easier than it is if you use cUrl or Sense if you don’t know the context.
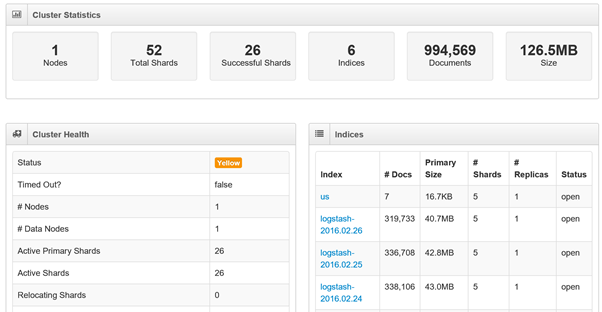
Here we see an Elastic Search instance running on a single node, we have 52 shards in total of which 26 are successful, and the remaining 26 form the replica of the first 26, if we had another node online they would be distributed to the other node and marked successful. We have 6 indices with a total of just under a million records, the majority of which are in one of three LogStash indices. The overall status is yellow due to our lack of replication.
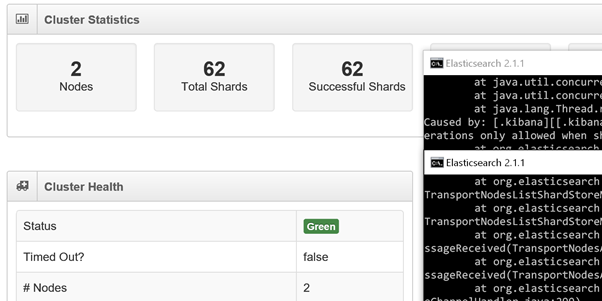
With two instances of Elastic Search running we can see our server status go to Green as we can now perform replication across all of our shards. In practice this configuration would be a little pointless in a production environment as you would be replicating to the same server and sharing resources.
Once a set of log files have been processed by LogStash and are present in Elastic Search we can begin our analysis using Kibana. In the examples below I will be using a set of test data that simulates messages generated over a period of three days.
Looking at a histogram of our logs we can see that between the hours of 04:00 and 07:00 (label 1) each day the volume of log messages is significantly lower than at any other point, this is likely to represent the period between the completion of our batch and the start of the next business day. We see most of our activity between the hours of 18:00 and 03:00 (label 2), this might suggest our batch is processing during this time. Between the hours of 08:00 and 16:00 we see a steady amount of activity, likely to be a mix between server and user activity over the course of the working day. The slightly out of the ordinary drop-off that occurs at 17:00 might be explained by the majority of the users logging out and going home between 17:00 and 18:00. By using the Visualise module we can create a graph that buckets our data by user to see if the above theory holds water.
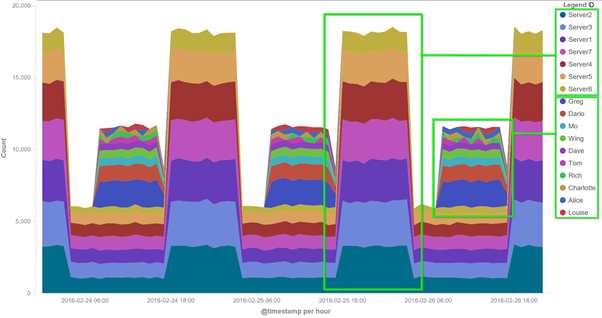
By doing this, we can see that the theory is pretty accurate, we can see user activity spiking during working hours and server activity spiking over-night.
In order to target these errors efficiently we need to know which are most prevalent, this is easily accomplished by creating a data table in the visualise module.
Please note that the example messages in this article do not accurately reflect those generated by a real OpenLink instance and are used purely as an example. The purpose of this article is not to describe a way to fix every type of message generated but to provide a mechanism for targeting messages in an efficient way.
The table tells us that the message ‘Invalid Table operation’ is the most prevalent amongst our logs. This type of message can be generated both by the core application and by custom code (OC, JVS etc.). We might be able to find out more with a simple dashboard.
Here we have a dashboard that combines our top 10 error messages, top 5 modules (Master, Script Engine etc.) and top 5 scripts. We can then filter the dashboard in a variety of ways.
Filtering on the most prevalent error adjusts the module and script top 5 totals to show where the error is most prevalent. If we wanted to concentrate on fixing the scripts generating the most errors we can filter on the scripts instead to see which errors each are generating.
For certain error messages OpenLink includes identifiers as part of the message. Only the column numbers differ in the following messages and could all have been generated by the same line of code if it were contained in a loop.
Invalid column number in table for Col=1
Invalid column number in table for Col=2
Invalid column number in table for Col=3
Invalid column number in table for Col=5
This type of message can be handled by unifying the data (in this case replacing the column numbers with a single value) before it is imported. Failure to accommodate this eventuality is likely to lead to Elastic Search painting a skewed picture of your log data. In the following screen-shot we can see that no single ‘Invalid column number’ message generates more than 4,685 messages for a given ID, however when unifying the data we see that by combining all variations of the same message we see a more concerning figure of 72,815.
As already mentioned, this article is not intended to describe how to fix each and every message generated by an Endur/Findur instance. For the many messages the fix is obvious and usually involves either a change to some configuration or a minor code change. For others a fix may not exist, many users experience an up-tick in error message generation during an upgrade or when configuring as yet unused areas of the system. For such messages, it is important that they are reported to the vendor so that fixes can be put in place or workarounds established. There is often a tendency to ignore such errors or manually implement suppression rather than report them. With both of these approaches there is a risk that vital information is missed or unavailable during a production outage and the overhead involved with keeping track of what is being suppressed/ignored and why becomes ever greater.
Real-Time Analysis
Once Elastic Search has been used to retrospectively analyse historic log files, the next natural step is to start using it for real time monitoring. Productionising an Elastic Search instance is described in detail in the Elastic Search documentation so I won’t describe the details here. It is however worth highlighting a few things pertinent to implementing near real-time monitoring with OpenLink in mind. In my previous article I demonstrated that the fastest way to log is to a local disk and that when OpenLink logs to the core logs it does so asynchronously. In order to improve performance it is worth considering pointing the OpenLink logs to a local location on each of your servers, remembering to implement an aggressive retention policy to ensure the disks don’t fill up. With the logs saved locally you can then make use of another product in the Elastic suite called a Beat. The job of a Beat is to monitor and process log files and feed them directly to Elastic Search. With a Beat installed on each server log files can be processed synchronously, any OpenLink processes do not have to wait as long (as if they were writing over the network) to process errors before they can continue.
Another important aspect of Elastic Search when used for near real-time monitoring is its ability to find anomalies in logging data. Using the Watcher add on, alerts can be configured to monitor for changes to your data. For instance, a simple aggregation could be configured to find the most uncommon messages among your dataset, an alert could then be configured to alert if the list changes. If a message not previously seen is generated by the application, the alert would trigger and lead to further investigation.

By selecting the single rogue message in the bottom 5 list we can immediately find the details of the message and begin our investigation.

With this we have found the proverbial needle in a haystack in a matter of moments, something that would not have been possible without a tool like Elastic Search. This is just the tip of the iceberg when it comes to the types of aggregations it is capable of. With more complex aggregations it is possible to provide alerts for a variety of situations that highlight potential issues with the application that may have otherwise been missed or taken longer to propagate were Elastic Search not in place. At KWA, we have experience configuring Elastic Search and other similar monitoring and analysis tools in the context of OpenLink, if you would like further information or a demonstration please contact us.